Into the feed of Currents, an open Pinterest alternative built on AT Protocol
May 1, 2026Over the past few weeks, I’ve been inspired by the many developers building new social apps on top of Bluesky’s AT Protocol, and I decided to start my own project: Currents, an open and decentralized alternative to Pinterest.
I published it a few days ago, still in “alpha”, and the code is available at this link. I’d also like to use this project as an open, public laboratory where I can experiment with topics that interest me but that I don’t get to explore in my day job.
One of those areas is recommendation systems. In this article I want to describe how I built the first version of Currents’ feed, which has the distinctive feature of being more or less personalized depending on the user’s preferences.
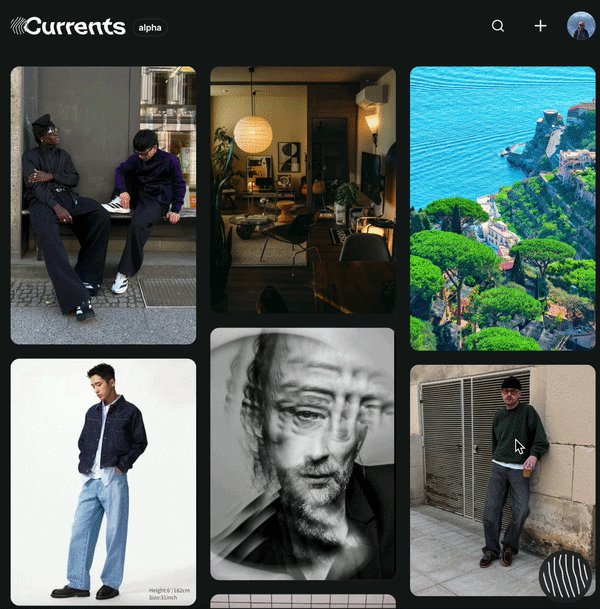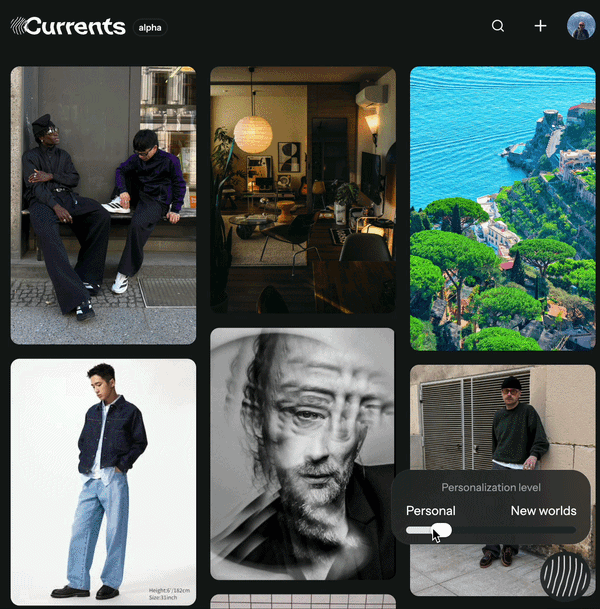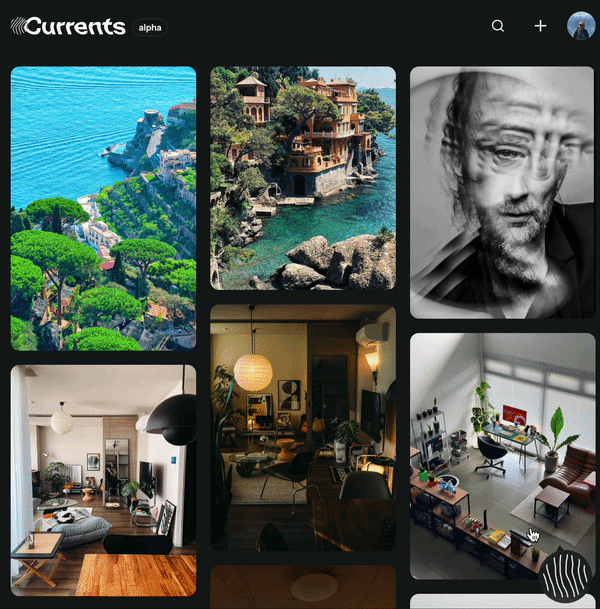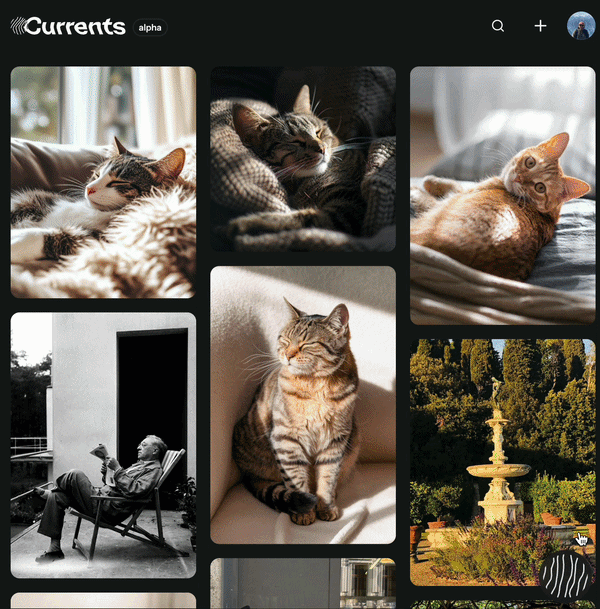
With this slider, users can adjust a parameter — which we’ll call α — that controls the level of personalization of the feed. Here’s an overview of how the system works.
From pixels to embeddings
The first part of the system transforms every saved image into an embedding: a 768-dimensional vector that encodes the meaning of the image. Images are mapped into a shared 768-dimensional space, where vectors representing similar images are close together, and vectors corresponding to semantically distant images are far apart.
These vectors are stored in a column of a PostgreSQL database (using the pgvector extension), which, thanks to an HNSW index, allows efficient retrieval of the nearest vectors to a given input.
The model used to produce these embeddings is SigLIP 2, which has a notable property: it can project both images and text into the same vector space. This means it’s possible to do text-based image search by turning a query string into an embedding and using it to retrieve the most similar image vectors.
Personalized feed
To build a personalized feed, I drew inspiration from PinnerSage — Pinterest’s recommendation system published in 2020 — and from how Bluesky’s Discover feed is generated, with some simplifications to keep Currents as lean as possible.
Both of those approaches run a clustering algorithm on embeddings to create groups of pins or posts, from which representative items of the user’s taste are drawn. Instead of running a dedicated clustering step, I decided to use the user’s own collections as clusters. Every time a user saves a new image to a collection, the medoid of that collection’s embeddings is recalculated — that is, the item that minimizes the sum of squared distances to all other items in the collection — and used as the representative embedding for that collection. Using the medoid rather than the mean of the vectors ensures that the representative always corresponds to a real image the user chose to save.
To generate the personalized feed, the medoids of the user’s 3 most “important” collections are taken, and a similarity search is run across all embeddings in the database, retrieving the items most similar to those 3 reference points. To determine which collections are most “important”, I used the same formula as PinnerSage, which weights saves by recency:
One downside of this approach is that users don’t always organize their collections by topic — for example, someone might create a collection called “2026” containing everything they saved that year — meaning the collection medoids may not be truly representative. Using a dedicated clustering algorithm could be more effective; that’s an experiment I plan to run in the future, once Currents has enough users to measure the impact. For now, this is the simplest and most practical approach I’ve found.
Serendipity
On the opposite end of the slider from the personalized feed, there’s the label New worlds. When the slider is moved toward that end, the feed follows a concept called serendipity.
Most recommendation systems we use today optimize for accuracy: they try to show us more and more of what we already like. A well-known downside of this approach is the filter bubble problem: users end up seeing only content that fits their existing tastes, limiting exposure to anything new or different.
For a creative person, I think this problem is especially relevant. Serendipity aims to solve it by maximizing recommendations that are unexpected yet still somehow relevant.
While it’s difficult to measure serendipity objectively, I decided to build a system that follows this principle and use it as a baseline for future experimentation.
The implementation is straightforward: once a day, a clustering pass is run over the entire image space to group images by similarity. (Dimensionality is first reduced to 50 dimensions using UMAP, and then HDBSCAN is applied for clustering, mitigating the so-called curse of dimensionality.)
Feed generation then works similarly to the personalized feed, with one difference in the 3 reference embeddings: instead of using the medoids of the 3 most important collections, for each of those collections we take the medoid of the nearest cluster whose items the user has never saved.
This forces the recommendation of items from clusters the user hasn’t explored, while keeping them adjacent to their known interests.
The α parameter
The two methods described above correspond to the two extremes of the slider’s spectrum. The slider controls α, which ranges from -1 to 1 and can take any value in between. This allows blending recommendations with a global feed: for example, with α=0.4, 40% of the suggested images come from the personalized feed and 60% from the global feed; with α=-0.7, 70% come from the serendipitous feed and 30% from the global feed.
The global feed ranks images by novelty and popularity using the following formula:
Conclusions
This project will be a personal laboratory for experimenting with interesting ideas, but I also hope it becomes an app that genuinely solves problems that users of similar apps face. I’ll keep listening to make it something that truly works for them.
Thanks for reading :)
Matteo
[1] Pal, Aditya, Chantat Eksombatchai, Yitong Zhou, Bo Zhao, Charles Rosenberg, and Jure Leskovec. “PinnerSage: Multi-Modal User Embedding Framework for Recommendations at Pinterest.” Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, July 7, 2020, 2311–20. https://arxiv.org/abs/2007.03634
[2] Wesley-Smith, Ian. “Personalization at Bluesky: The past, present, and future of personalization of the Discover feed.” RecsysML + LLMs, February 23, 2026. https://recsysml.substack.com/p/personalization-at-bluesky
[3] pgvector — Open-source vector similarity search for Postgres. GitHub. https://github.com/pgvector/pgvector
[4] Hierarchical navigable small world (HNSW). Wikipedia. https://en.wikipedia.org/wiki/Hierarchical_navigable_small_world
[5] Roy Gosthipaty, Aritra, Merve Noyan, and Pavel Iakubovskii. “SigLIP 2: A better multilingual vision language encoder.” Hugging Face Blog, February 21, 2025. https://huggingface.co/blog/siglip2
[6] McInnes, Leland, John Healy, and James Melville. “UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction.” arXiv:1802.03426, February 9, 2018. https://arxiv.org/abs/1802.03426
[7] McInnes, Leland, John Healy, and Steve Astels. “hdbscan: Hierarchical density based clustering.” Journal of Open Source Software, 2(11), 205, March 21, 2017. https://doi.org/10.21105/joss.00205